Summary
Jake Ryland Williams
Assistant Professor
Department of Information Science
College of Computing and Informatics
Drexel University
Some themes
Google's PageRank search is an excellent DS example.
It grew early, in an environment of very large data,
and spun off important tech developments, like MapReduce.
Google search dev. covers many DS lifecycle components
like acquisition, pre-processing, modeling, and optimization,
and is rolled out with updates that affect human lives.
Putting things together
We've seen DS requires a lot of different skills,
with projects that engage many different tasks.
What we haven't done yet is see how they all fit,
which we will do here in a well-known example.
So, we'll motivate a real-world data science problem
and note key technical steps along the way
and how they represent the data science life cycle.
Web search
Without web search the internet would be a blind world.
Navigation would consist of pages known, their links,
and "stabbing in the dark" at arbitrary URLs.
In the early days, web search was much more limited,
and there were many well-used options for finding pages,
like altavista, Yahoo, WebCrawler, Lycos, Ask Jeeves,
and many more..., including Google!
These web search sites work(ed) in a variaty of ways.
However, Google works really well, and outpaced all.
Why is Google a big deal?
Web search requires an index of searchable items,
and all engines have this in some way or another.
Search engines have to filter items according to the search,
which usually involves matching terms in html body text,
or possibly metadata tags that provide context.
But even with a filtered list, the big problem is ranking,
i.e., which pages should be at the top of a search?
This is where Google really made strides in the business,
when they created and employed the PageRank algorithm,
which was an excellent example of successful data science,
touching clearly on key life cycle steps, including acquisition,
analysis, modeling, production, and optimization.
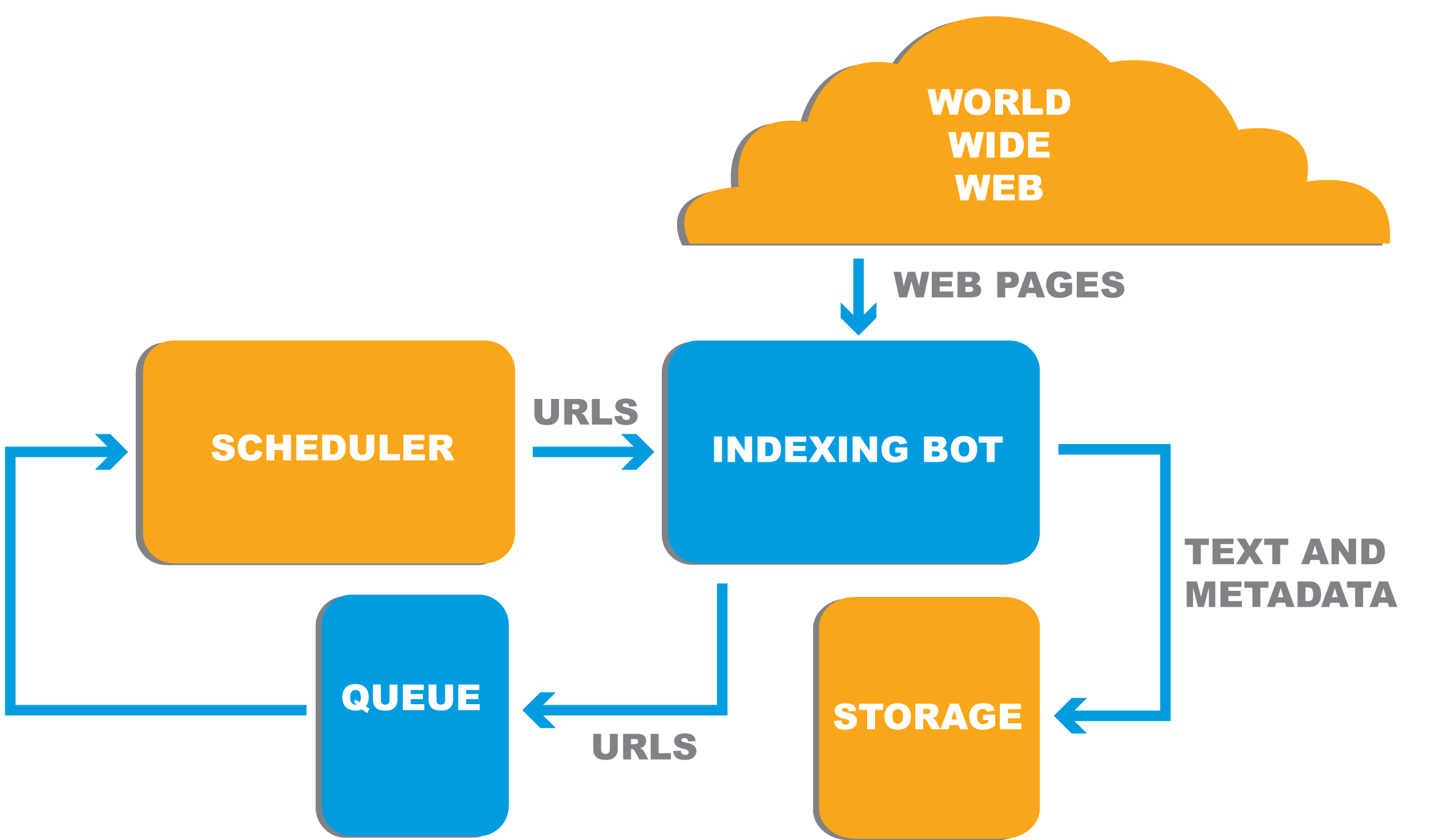
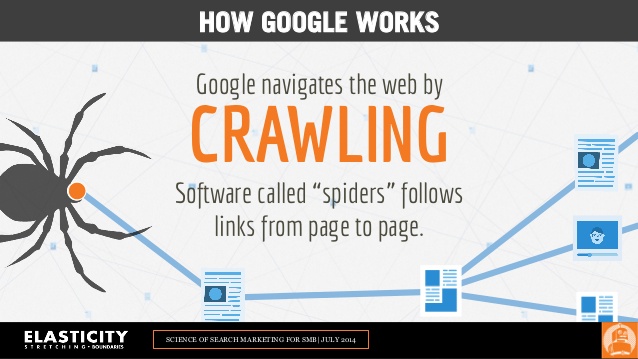
Crawling the web
An index of html is necessary for Google's web search,
and they do this by crawling the web with Googlebot.
Googlebot starts by visiting a list of known pages.
Adding any hyperlinks to the list to crawl.
Any new sites, or changes to existing sites are processed,
updating Google's master index.
This results in a lot of data—not just the urls,
but any of the search features that they use to filter.
MapReduce was originally coined for proprietary Google tech,
but has since be genericized built out open source for use.
Web crawling is Google's big data collection step.
Indexing
When google finds a new web page it indexes it.
Indexing a page involves recording the url itself,
its words and all of their locations,
and key metadata and html tags, like Title, etcetera.
The data are all primarily used for filtering,
but the indexing process also includes finding outlinks,
but these don't just make the index bigger.
The outlinks from a page are used in the ranking process,
which we will see tie directly into their analytic model,
but for now, indexing is a great example of pre-processing.
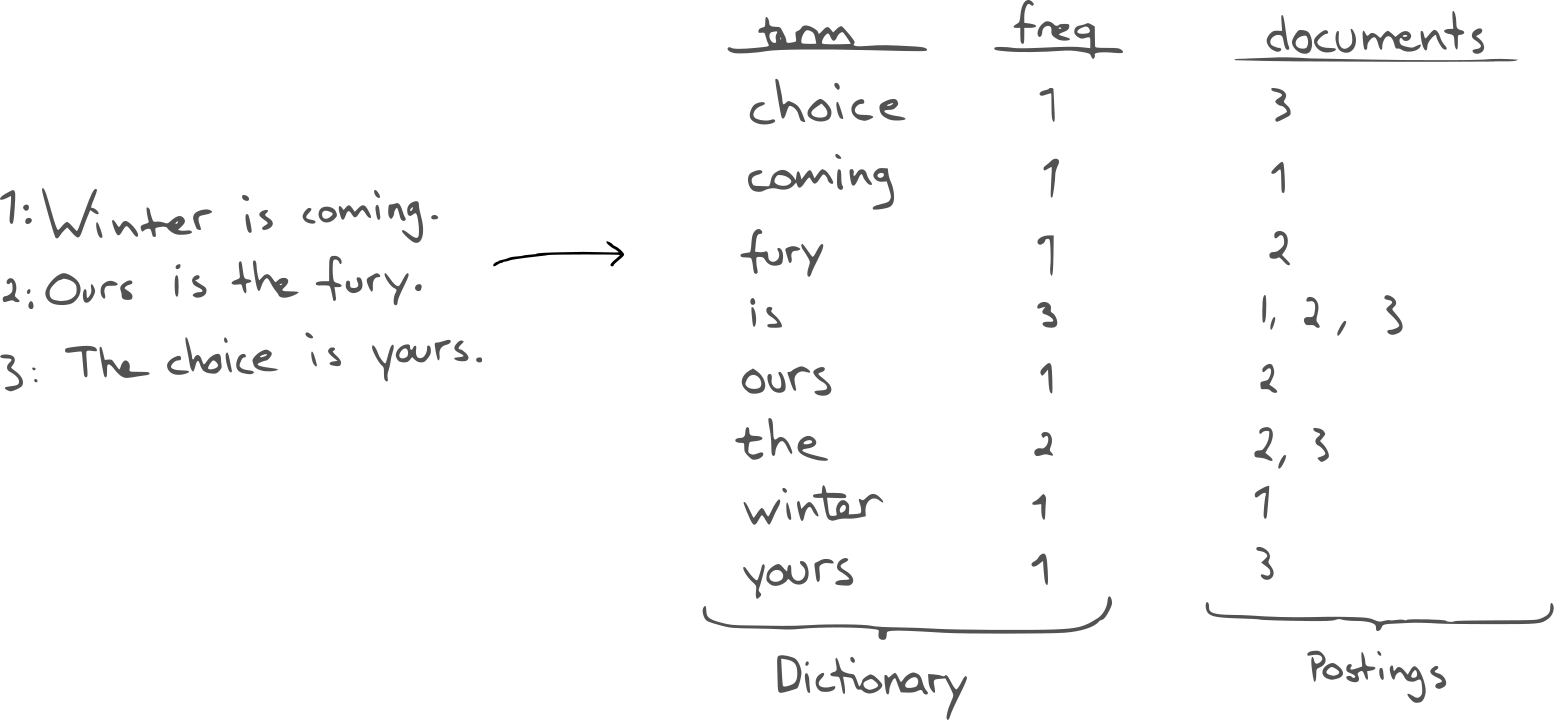
Inverted indexes
Inverted indexes are core essential to page filtering.
A common index describes the contents of a document,
which is good for knowing what's inside,
but this information is backwards for finding documents,
i.e., a program would have to look through all documents
in order to find those matching a word (CPU expensive).
This should ideally be done once, with the info stored,
which is precisely what an inverted index accomplishes,
i.e., an inverted index says which documents have which terms.
The Internetwork!
Google's big innovation was really with ranking,
and this was done by putting the problem into a good model.
The internet can be viewed as a bunch of linked documents,
which is abstractly a directed network of links and nodes.
The connections, themselves, possess a lot of information,
which Google extracted with a mathematical model
finds where a "person" might most frequently arrive
as they "surf" around the internet randomly.
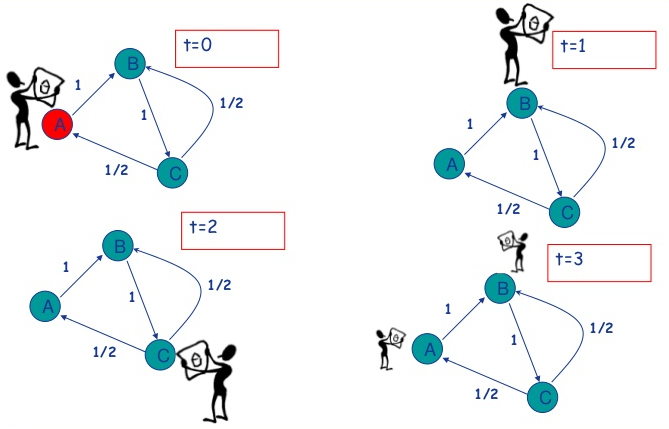
A random surfer
With the internet as a network of links and nodes,
Think of Google's PagrRank starting a surfer at each page,
at each step forward in time, surfers click onto another page,
choosing one linked from where they are.
This happens again and again, until the game stops,
and finally Google check to see where people wound up.
The places with the most surfers are the highest ranked,
and those with fewer are lower ranked.
Random surfing is an excellent network modeling example.
A surfer walks randomly
PageRank
The random surfer model is intuitive and understandable,
but executing PageRank with it is somewhat more complex.
The model uses a lot of linear algebra,
since a network is represented by an adjacency matrix,
and it is generally computed in terms of probabilities
that describe the likelihood a surfer will chance upon a page.
However, some pages don't link out anywhere,
and some groups of pages are entirely disconnected,
which causes the page-hit probability to bleed away.
To fix this, the modelers included teleportation into the model,
where a surfer jumps to an arbitrary page with a probability, p,
or follows a link from locale, with probability (1-p).
If you look this up, p is often called the "damping" factor.
PageRank
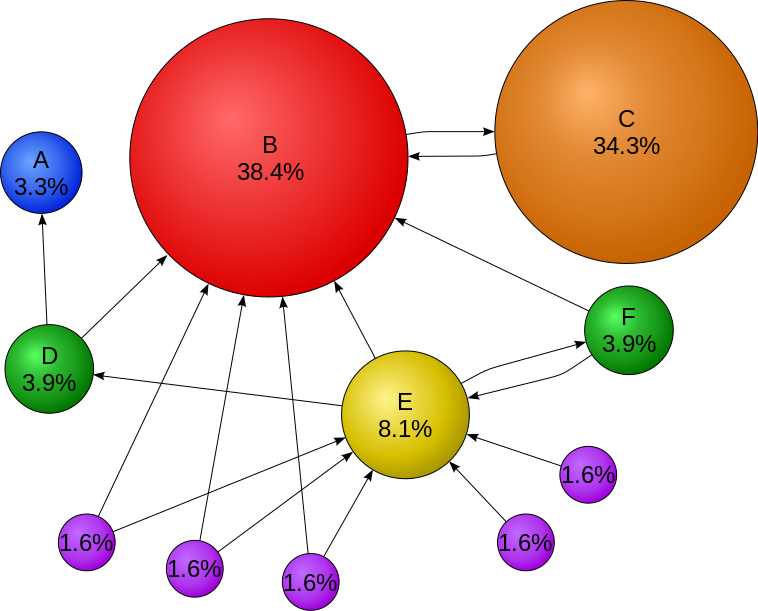
Page C has a higher PageRank than Page E, even though there are fewer links to C; the one link to C comes from an important page and hence is of high value.
Spamdexing? Link farming?
PageRank is a powerful algorithm, but publically known,
and people learned to game it for better ranking.
"Spamdexing" is a general term to cheat indexing systems,
and "keyword stuffing" pages helps them pass filtering,
but "link farming" was devised to cheat PageRank.
Incoming links contribute to a page's score the most,
so a collection of pages can be strengthened by crosslinking,
but sites eventually started trading links for better PageRank;
some were created for the sole purpose of selling links.
Amidst growing concerns, Google modified their algorithms,
identified thin-content websites, and demoted them in rankings.
However, "good" sites were hurt in the process, and
much user interaction was required to optimize search quality.
Nowadays, search engine optimization (SEO) is a science,
where companies seek consulting to improve Google presence.
Personalization
Not all of Google's optimization fights black-hat SEO.
By 2009 personalized search was applied to all users;
website cookies informing of previous browser searches
enabled Google to direct searches to related pages.
Most users have no idea this is going on when they search,
but the service was slowly rolled out through chrome users,
and determined appropriate for mass use, eventually.
But determining site rankings for SEO is now difficult,
and users can be trapped in "filter bubbles,"
where they don't see information outside their own views!
De-personalizing Google is actually fairly involved.
While disabling used to be possible at the search bar,
this is no longer a feature that can be turned off,
but only mitigated, by blocking location reports and cookies.
Recap
Google's PageRank search is an excellent DS example.
It grew early, in an environment of very large data,
and spun off important tech developments, like MapReduce.
Google search dev. covers many DS lifecycle components
like acquisition, pre-processing, modeling, and optimization,
and is rolled out with updates that affect human lives.