Life cycle
Some themes
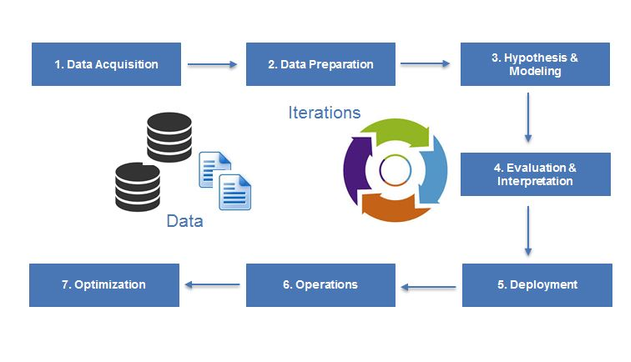
The data science life cycle
Practicing data science
- Some rules of thumb to overcome common challenges:
- Don't just assume, let the data speak.
- Avoid ad-hoc explanations of data patterns.
- Focus on communication for broad audiences.
- Plan for the unexpected amidst noisy input data.
- Beware the transition from prototype to product.
- Take time to understand statistical procedures.
Facebook is going to die?
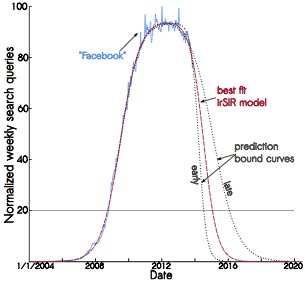
- One example fail:
- Princeton researchers discovered Google trends.
- They saw patterns for the terms: "MySpace" and "Facebook."
- They applied an infection model to search-term data.
- Conclusion: MySpace failed, and both fit the model,
- so Princeton predicted Facebook would collapse by 2018.
No, Princeton will dissappear!
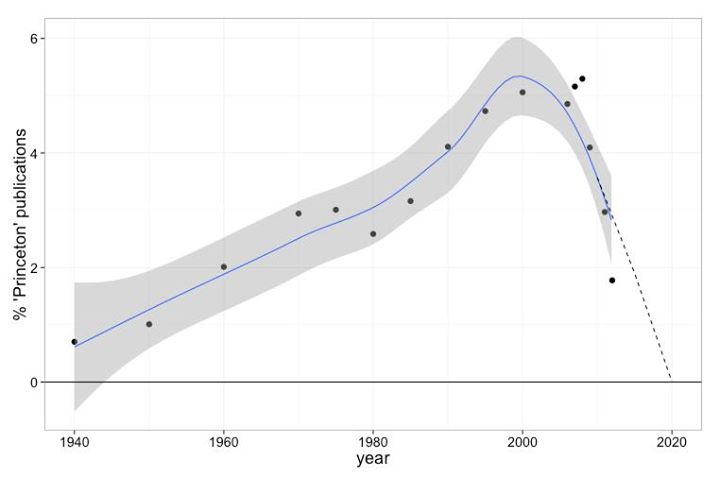
- Facebook eventually struck back!
- Applying the great theory of correlation => causation,
- Facebook concluded Princeton would disappear!
There should still be a scientific method
Naturally, this is close to CRISP-DM
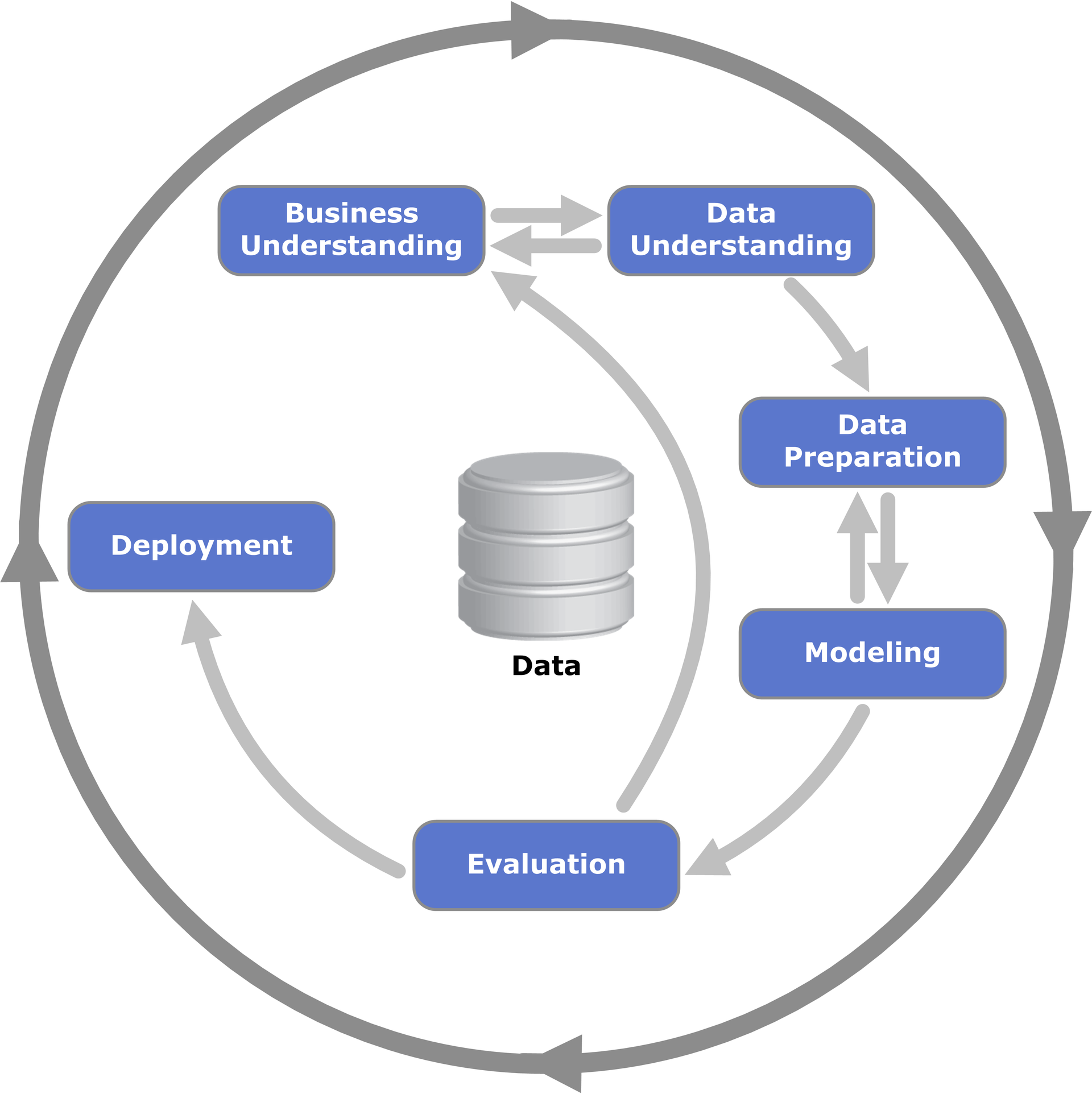
Differing scientific methodologies
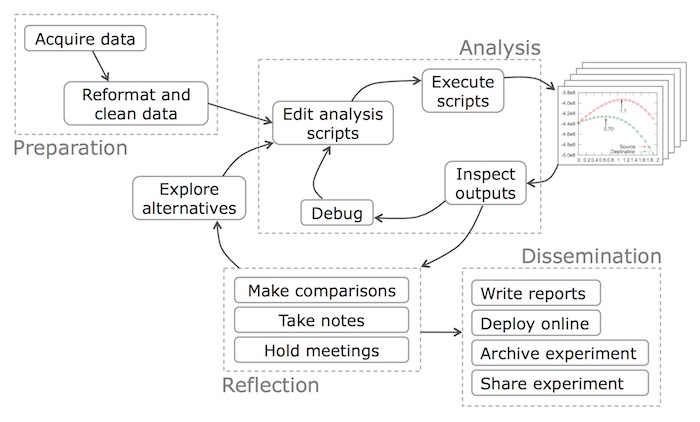
Similar tasks in a "work flow"
Required readings
> Differences for Building data products> CRISP-DM
> The Data science project lifecycle
> A data science work flow
Next: we'll go into some lifecycle specifics
Acquisition
(making acquisition easy).
Preparation
- Frequently, data does not come in a convenient form:
- it can be structured or unstructured,
- may be factored with dependent records,
- may be in the wrong units, rife with NAs,
- or even just spread across multiple sources.
Modeling and hypothesis
- Some rules of thumb:
- explore first with descriptive analyses and figures
- characterize data from every angle
- decide what questions might be answereable
- review models that can confirm/deny hypotheses
- choose models are practical to implement
Evaluation and interpretaion
- Some good practices:
- test initially on a little data you know inside and out,
- and make lots of sanity checks—is it working?
- always save output and visualize separately
- focus closely on model tuning and interpretation
- does the output appear as expected?
- if yes, then double-check that all code is correct
- if no, then still double-check for broken code
- but really focus hard on interpretation,
- because unexpected results can be the most impactful!
Deployment
- Some good practices:
- start with a pilot program
- set low expectations for users
- start with limited functionality
- clean and simple pays off at the start
- documentation can save a lot of headaches
Operations
- Some good practices:
- make sure users can report problems
- make sure someone is regularly checking reports
- focus on minimizing reported product friction
- if a product breaks, go back and adjust the pipeline
- update documentation reflect product changes
Optimization
- Some good practices:
- keep track of the market and competition
- stay current on methods and technology
- monitor growing user bases and their impact on the system
- stay current with design
- always look for efficiencies
- don't leave around unused features
Recap
- Up next, all about data:
- Overview of types of data.
- What makes different types different?
- How organization defines data.